
快速和节省资源:The Graph 的代价在于,他可以很是快速的用数据答复很具象的问题。他们举了个例子:对付 CryptoKitties, 可以查询在 2018 月之间 1 月到 2 月降生的 Kitties 的所有者是谁的问题,这就需要遍历智能合约的 birth 事件,以及 ownof 要领。这样一个问题大概需要几天时间才可以。The Graph 的子图就是办理这些问题的索引。
SubQuery 是专注于波卡生态的数据提供方,可以转换和查询 Web3.0 生态数据。SubQueary 受到 The Graphh 开导,也是利用的 Facebook 开拓的 graphQL 语言。SubQuery 面向所有的 Polkadot 和 Substrate,而且提供一个开源 SDK。相对付 The Graph, 作为开放市场的 SubQuery 中的脚色有三个:消费者、索引这和委托人。消费者宣布任务,索引这提供数据,委托将空闲的 SQT 代币委托给索引者,鼓励他们更多的厚道参加事情。代币经济学和 The Graph 雷同。
一般有两类有代价的数据:
数据的提供者
雷同于 The Graph 的项目尚有 Covalent,提供了一个数据查询层,让工程师可以快速的以 API 的形式挪用数据。一个简朴的 API 就可以办理所有 Covalent 支持的链的数据。Covalent 的数据集较量完备,可以多链多项目标一起查询,不需要很强的 coding 基本。Covalent 也有本身的代币 CQT,代币持有者可以用来抵押、投票(数据库上新)。Covalent 有两类 endpoints,一类是区块链全体数据范例,如余额、生意业务、日志范例等;另一类是对某一个协议的 endpoint,如查询 AAVE 的日志。Covalent 最有特点的是跨多链查询,不想需要从头成立雷同子图的索引,二是通过改变 chain ID 就可以实现,query 的可扩展性大大加强了。
将来数据市场的驱动力主要有四个:多链宇宙(含 Layer2)的成型, 应用的增加和用户的增加,应用带来的数据需求的增加(如开拓、阐明、生意业务、金融产物的利用等),用户行为巨大化。可是数据状态也不会爆炸下去,也会颠末一波整合,和 Gartner 成长曲线雷同。
Mem 欣赏器,通过 API 形式的可以订阅 mempool,可以准确到任何一一个协议中,好比 UniswapV3, Sushiswap 的相关生意业务在 mempool 内里的表示Gas 平台,通过及时 mempool 数据来预测 gasfee 的东西模仿平台成果,模仿 mempool 中检测可被执行的事务,并按照当前块高度对它们举办模仿,以显示它们的结果。只要切合 Blocknative 检测法则的生意业务举办模仿SDK 平台,种种网站可以通过 javascript 挂接 Blocknative 的 API,来显示该网站产物的生意业务执行环境Blocknative 是专门针对 mempool 举办侦测的数据网站,因为 mempool 的数据和最终区块数据不会一致,其实时性和其他数据 indexing 比要求跟高。以太坊有一套巨大的系统来打点 mempool 中的生意业务,Blocknative 提供的字段查询越发即时和准确。
以太坊的本质是生意业务驱动的状态机,一切变革皆由生意业务开始,变革的记录就是数据,API 从新到尾串起了数据的流转。整个区块链数据流转的进程是这样的:
本身搭节点就是本身将所有的以太坊全网数据全部下载下来,这需要大量的本钱,以及安详技能,大部门用户和开拓者都不会选用这样的模式去利用数据,一般会利用第一类要领可能直接从去找到更好的 API 处事商。
好比借贷协议需要监控账户状态,一些自动化中间件要实时反馈价值变革等。
数据处事商的代价晋升仍然有很大空间靠得住性的晋升
Infura, Alchemy 和 Quicknode 均各自有一些知名用户:
长途会见以太坊的节点
数据查询的流程遵循以下步调 :
我们认为数据市场需求发作的驱动来自于:
以太坊的主要字段是 State Root(状态树),包括了账户余额、声明、随机数等,状态树回收的是 Merkel-Patrica 布局,需要不绝的更新。而生意业务树和收据树不需要更新,所以回收了 Merkel 的数据布局:生意业务数据是永久数据,永久数据已经记录不会被改变。状态树储存每个以太坊账户的地点余额,一经产生生意业务就会修改。以太坊的数据布局总结起来就是这一张图:

永久储存与姑且储存
如何会见以太坊上的数据呢?一般是两种方法 :
The Graph 提供了一个数据的搜索引擎,借助于 GraphQL API,用户可以通过 subgraph (子图)直接会见得到信息。并且 The Graph 是去中心化的,受到许多 DeFi 项目标支持。其也提供一些列成型的 subgraph (雷同于 Dune Analytics 用户的 query 可能 dashboard),供代码本领一般的用户直接利用。
本篇我们探讨一下区块链世界里的数据供给,以及以数据为焦点产物的处事商如何形成必然的市场局限,即他们如何发生代价和捕捉代价的。
用户数据从里层走向表层
除了上链的生意业务外,以太坊尚有一个生存在缓存中的数据,即 mempool 内里的列队数据。各个节点提交的生意业务城市被放入 mempool 生意业务池中,颠末序列化、生意业务验证、过滤等步调,最终选择符合的生意业务被矿工打包。生意业务池中有 Queue 和 Pending 两个 map,用来存储未验证生意业务和已验证生意业务。Queue 和 Pending 清理竣事后,按照差异节点提交的生意业务,生意业务池要举办重构(由于漫衍式的原因),防备呈现分叉。
生意业务者按照种种数据信息判定可生意业务的偏向,好比调查某条链的活泼水平,某个 DEX 的成交环境、某个借贷协议的借出贷款等。他们会需要有靠得住的数据源,一些高级用户会利用付费的数据处事。
需要不断监听网络状态的应用和中间
开拓者查询、挪用链上数据,与区块链交互。由于节点处事商的存在,开拓者不需要搭建本身的节点,就可以直接和链长举办交互。浩瀚 dApp 以及第三方钱包应用都依赖于 Infura 这样的节点处事商,与区块链举办交互。开拓者的需求来自于:网络状态监控、生意业务执行状况监控、不变的执行情况、市场和竞品趋势信息、产物和市场计策指定、按照客户偏好晋升产物机能等。
本身搭建节点,当地会见
查询索引处事层
非链上数据:与链上相关,精确性依靠中心化或去中心化的节点验证的数据,如生意业务所、预言机等,雷同于 Web2.0 处事。生意业务所数据介于链上链下之间,是链上数据的链下计较,然后经链上验证,也发生了很大的数据量。
如前所述,以太坊的底层数据是以 K-V 形式储存在底层 LevelDB 里的。可是 LevelDB 适合于写多读少的场景,所以真正用于读取、查询的数据库是 StateDb,它打点着所有账户的荟萃,账户的泛起形式是 stateObjectStateDB。其直接面向业务,是底层数据库(LevelDB)和业务模子的之间的存储模块。它回收两级缓存机制,以满意查询、更新、挪用等成果。第一级缓存为 map 形式,存储 stateObject,二级缓存以 MPT 形式存储。当 stateObject 有变换的时候,实例化的 stateObject 会更新,当 IntermediateRoot() 被挪用后,他们会被提交到 MPT 上,当 CommitTo() 被挪用后,他们会被提交到底层 levelDB 中。这就形成了三级缓存布局。利用多存数据库的长处是,当需要回滚的时候,直接挪用 stsateDB 中 MPT 树的根节点举办数据还原即可。
来历:https://etherscan.io/block/12912176
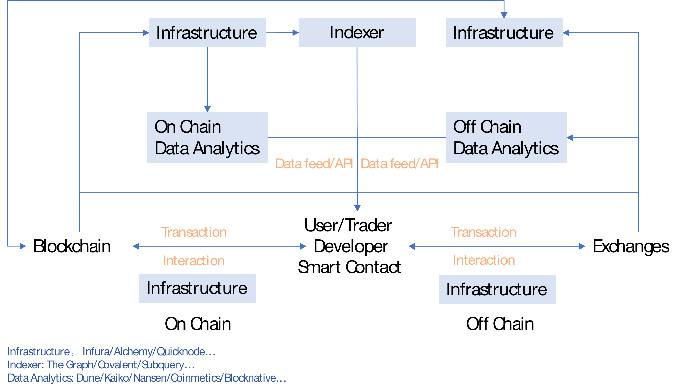
这一层主要是提供一整套链上可能链下的数据集或 API,利便于生意业务员举办阐明。
区块链并不符合举办文件的存储,以 IPFS 作为存储底层和区块链团结的方法是较量承认的,好比数据储存在 IPFS 中,可是数据的 Hash 值存在以太坊的状态数据库中。
多链宇宙(含 Layer2)的成型应用的增加和用户的增加应用带来的数据需求的增加(如开拓、阐明、生意业务、金融产物的利用等)用户行为巨大化数据市场参加者生意业务者
主要的产物有:mempool 欣赏器、网站 SDK、Gas 平台和模仿平台
Dune 先把区块链上的数据(主要是以太坊)举办理会,然后填充到数据库中,酿成一个 PostgreSQQL 的数据库。用户无需写剧本,只要会利用简朴的 SQL 语句就可以举办查询。Dune 起了一层将数据举办理会和名目化的浸染,还提供了可视化东西。以太坊是键值数据库,Dune 把它酿成一个干系型数据库,SQL 语句就是干系型数据库的接口。Dune 提供的数据表有:
很多区块链的布局也可以存储非生意业务数据,可是容量有限。好比比特币的 output 中的 OP_RETURN 字段就可以存储不高出 40 字节的数据。限制的原因在于放大增加这部门会影响区块链的机能。以太坊的区块头也有 Extra 字段可以用来写入数据,如这样的:
来历:HyperLedger

业务很传统:这些处事商体量都不大,颠末几年的竞争,上面提到的这些名字已经劈头跑出。他们根基都是中心化的项目,估值在几千万美元(市场的需求还没有完全起来)。业务逻辑容易领略,有传统的可比标的,数据合规做得好是很好的收购标的。
Skew 和 Zabo 直接被 Coinbase 收购,传统规模的资金也在参加。跟着多链时代的开启,数据量会成倍的增加。多链时代对行业是个检验,但对付数据公司来说,则打开了宝藏之门。The Graph 提供的统计显示,2020 年 6 月,天天只有 3000 万的 query,到了 2021 年的 6 月份,天天的 query 到达了 6.75 亿。
开拓者
来历:《深入领略以太坊》
用户数和用户行为的发作尚有一个潜在功效,就是当这个级别开始逐渐靠近互联网级此外时候,一些传统的数据挖掘要领就开始浮现出代价。Web3.0 上依然可以提供雷同 Web2.0 的处事,而有些数据固然是果真的,但却是只能被部门公司 access 到,者给以对用户行为阐明和打标签的本领。一个较量大的 gap 是,此刻用户的 Web2.0 和 Web3.0 身份还没有对应上,好比许多项目标用户,也很是努力的在 Discord 内里交换,他们和 Web3.0 的身份没有对应,这内里其实也会让许多时机。像 Nansen 就是把海量的钱包举办打标签,为数据用户提供真实的链上行为阐明,尤其是可以看到那些巨鲸的勾当。像 Nansen 这样的,将来针对用户数据的再挖掘,会让数据处事上的(处事)再上一个新台阶,好比 Zerion、Zapper、InstaDapp 这样的 DeFi 聚合层,也是可以很好掘客用户数据的平台。Covalent 也提供了对钱包的查询成果。
数据处事者范例节点处事层
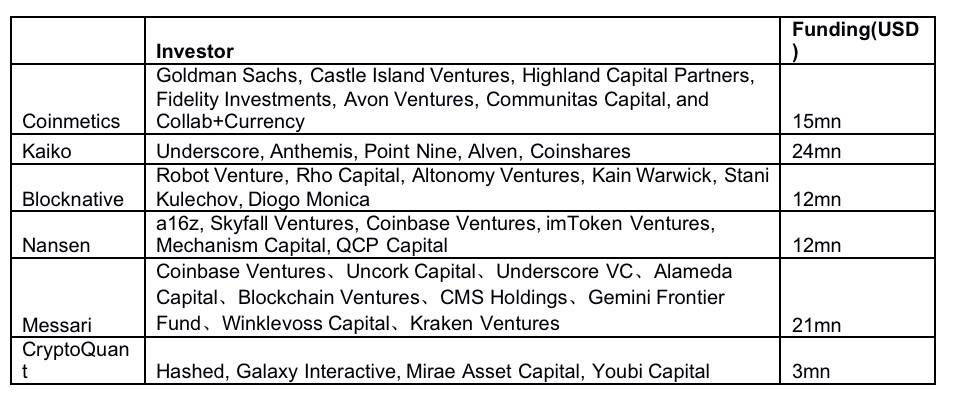
来历:网络,HashKey Capital 整理
数据阐明层
区块链的数据按照状态和生意业务的抽象布局如下:
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。










